
I've been able to publish on GitHub my whole infrastructure as code setup, this is the result of several weekends of code refactoring and rearranging data here and there in order to make it as modular and reusable as possible, here is the result:
 namelivia
nameliviaIn total the whole code is composed of one main repository, plus 7 Terraform modules and 37 Ansible roles. Even though the publishing is the result of the last week of work, it is built on top of the work I've been doing learning and changing the infrastructure for probably the last 5 years when I started hosting my first web application on a refurbished laptop placed on a chair in the corner of a room. Since then I've learned and experimented with containers, automatic provisioning, tried different cloud providers and configurations, and never had the chance to publish anything because I never took the time to rebuild it in a public shareable way.
It represents the current state of my personal infrastructure. Meant to host applications for me and some friends, relatives, or organizations I collaborate with, it tries to be cheap and targeted on a low budget and without scalability in mind. That's also the reason why the current topology looks as follows:
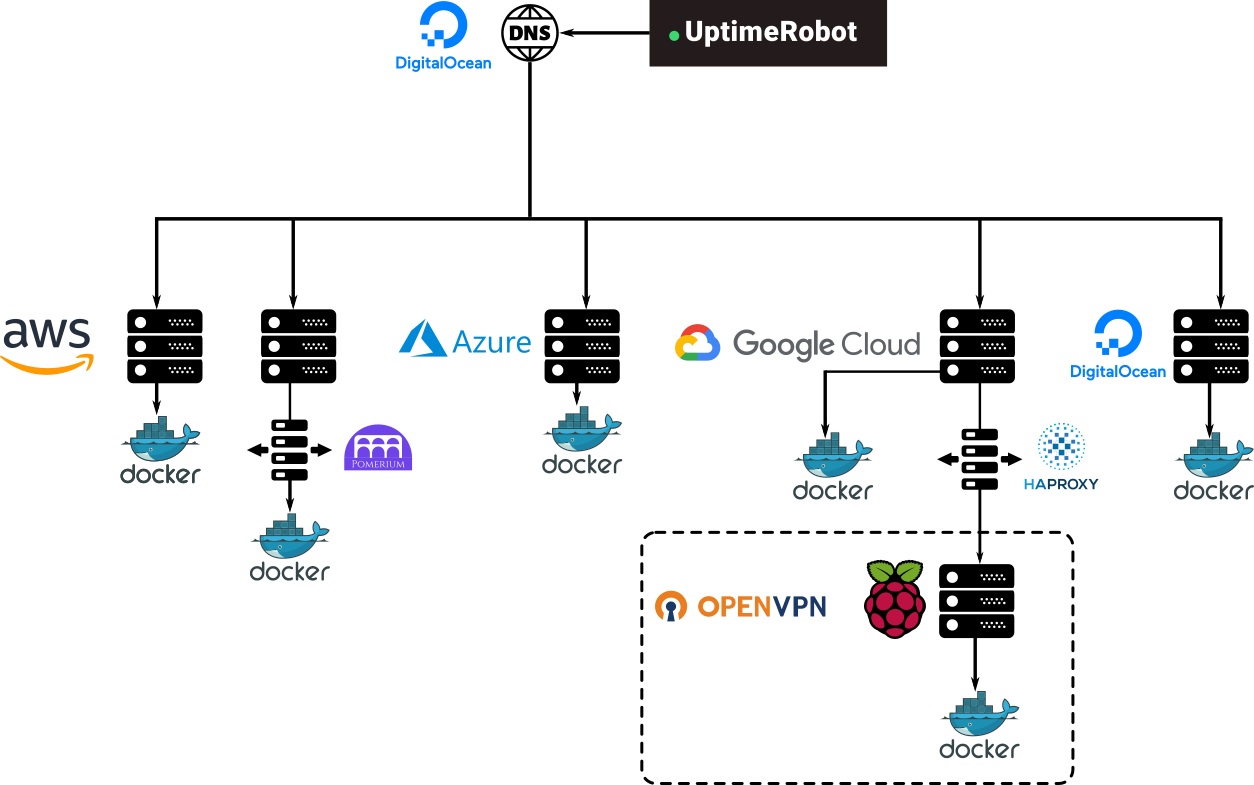
All the applications are shared among as many cloud providers as possible, the reason for this is to take advantage of the free layers of all these providers. But at the time of writing this, I've run out of credits on most of them so that's probably not desirable anymore.
Some key features drove the way I designed all this:
- Everything is a Docker container: All apps are containerized and deployed as Docker containers in order to facilitate the deployment and the interchanging of containers between machines.
- All it backed up on S3: In order to avoid data loss, databases and filesystems are periodically compressed, encrypted using GPG, and stored on S3.
- All logs go to Cloudwatch: All logs of all applications are sent to an external provider.
- It's cloud-agnostic: To avoid vendor lock-in it is all about Linux machines running Docker containers, I tried to avoid cloud-specific configuration so I can move things from one provider or even my own physical server.
There are still, of course, many loose ends here and there since my side-project time is limited, but I think I kept it from the eyes of the public for many years and wanted to share my learnings and mistakes with the general public.
Finally, everything will change over time according to my needs, in other words, there is no use case for anyone else but me but I'm sharing it for educational and showcasing purposes, even though this information is something a regular organization will keep in private, and I suppose I'm exposing myself to get hacked if I publicly share that I am running something misconfigured, but if that happens I will at least learn from the mistake!