
The problem
Recently I had to work on this issue of one of my projects hosted on Github and these are the notes I took. The repository contains a very old Ruby language tool I made for processing .XLS files downloaded from a bank website an apply some format transformations an so on the data, it used to work flawlessly... until one day.
For some reason, one day every .XLS file downloaded from their websites started to fail, the reason is that the Ruby XLS parsing gem I was using returned [] for the contained data on every cell of the Excel file. As I needed a fast solution, so I tried opening the file with Libreoffice Calc and... voilá, the tool not only correctly renders the file, it also lets you save the file as an .XLS file and then it will also be correctly parsed by the script.
This is a temporary solution, and also forces you to wait while opening a slow (no offense, I love Libreoffice!) software in order just to click the Save button and a confirmation dialog. Doing this every single time started to become tedious and I used my willing to rewrite my old Github repositories last month for trying to fix this once for all, however, doing this was a bit trickier than I thought at first.
Inspecting XLS files
Everyone with basic computer knowledge knows how to see the contents of an XLS file, just by opening it with your Excel like software. But for this particular case it is not enough, we need to see every single bit of information contained on the file whether it is meant to be rendered or not. Some of those bits are the ones messing with the Ruby spreadsheet parser and preventing it from extracting the information so my approach for solving this will be to:
- Get an original file
- Fix it using Libreoffice
- Hex-level compare the two files side by side.
- Identify the differences breaking the parsing.
- Create a script for automatically fixing original files.
I won't get into detail on steps one or two cause are unimportant, I will start writing on how did I manage to compare the files. For viewing the files side by side I used bless which is a nice cool and free software, included on the official Archlinux repositories.
By opening it using bless, and checking some documentation on XLS and CFBF we can identify the 512 first bytes as the CFBF header. As stated on the article previously linked:
The CFBF file consists of a 512-Byte header record followed by a number of sectors whose size is defined in the header.
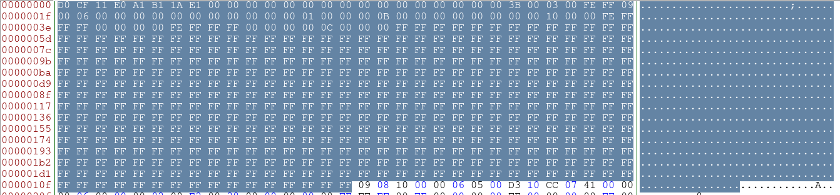
In this particular case, we can see that the fixed an original files are identical so we will assume the problem is elsewhere, so let's move on.
At this point I spent like two hours diving in the official almost 350 pages XLS format documentation by Microsoft while looking at the hex file, but I was not making any significant progress and was spending way too much time so I decided to take a different approach and take a look at the Spreadsheet gem source code, and started adding flags on this file.
There there is the get_next_chunk function that will be extremely useful to navigate the hex files as the program does by printing the position the pointer is in, and the codes it is looking for.
After hours of adding flags on the gem source code following the execution flow I found some interesting difference on both original and fixed files, in both files while reading the worksheet chunks containing the missing data are found because these can be identified by the code stored in the op variable. Following the execution of that function, if the operation is included in ROW_BLOCK_OPS which is the case, it will execute a function called set_missing_row_address that will look for the operation row index in worksheet.offsets and here comes the difference, on the fixed file this variable is filled with the row indexes and their addresses while on the original file this is not populated yet.
This is because for the original file, the contents of the row are read first, and the array of worksheet offsets is created, and then the rows are read and the offset array is overwritten, while on the fixed file the rows are read first and when reading the contents the array is already filled. At this point I wondered, What if I modify the gem's code and comment the :row ops parsing? I got lucky and the script correctly parsed my files, cool. But this was not a proper solution and at this point I decided to get in contact with the gem maintainer for discussing it by creating a Github issue.
What's written there is the result of my investigation during that time and the advices by the project maintainer. I found out that for some reason, the Caixabank's Excel file was being incorrectly structured and it was not worth it to modify the gem code for this particular case, instead I found that skipping some code on a method called read_worksheet will make this particular files to work.
So my next step was to somehow make this method do nothing but just when running for this script, I found out this is called Monkey Patching and Ruby is specially suited for this kind of 'hacks'. However, this is considered a bad practice (as the name suggest), but this scenario seemed so fitting that I guess I can make an exception if I handle the bad practice with care. I read about good practices withing this bad practice, and decided to use class_eval and prepend would be safe enough. Tried it and... it works! :)
So I finally closed both issues, created my patch pull request and finally tagged my repository as the 0.0.1 version.
Phew! It actually took a while getting here, specially since I work on this kind of projects in my spare time, but marking and issue as fixed worth it. There is still a lot of room for improvement, and I have some ideas for the next release so... until then!